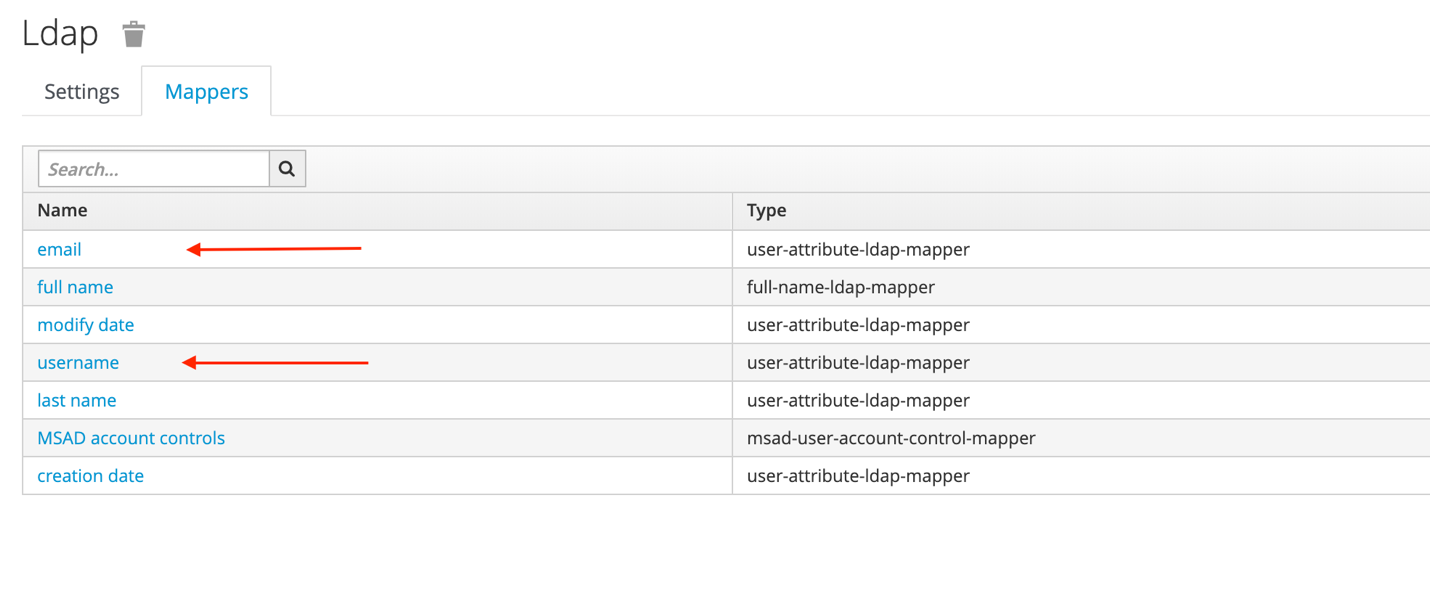
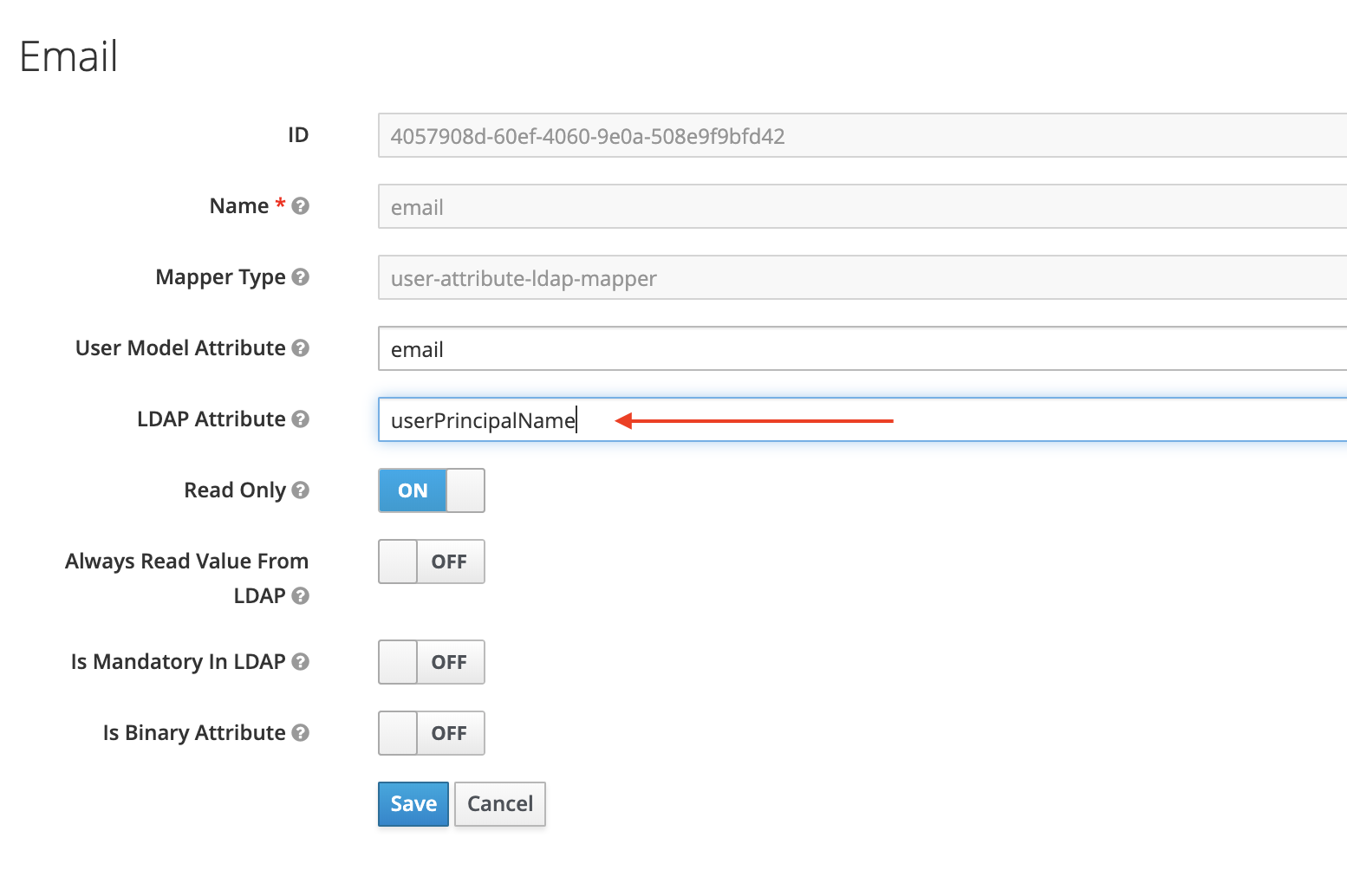
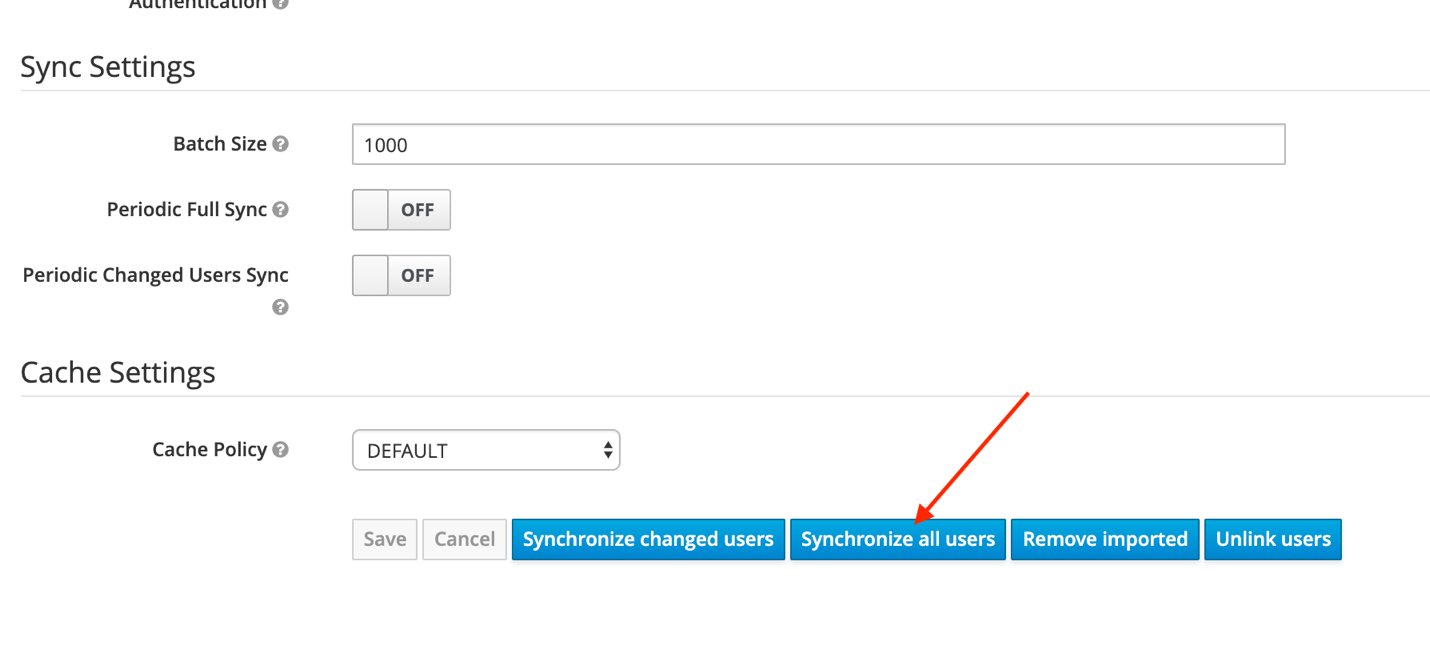
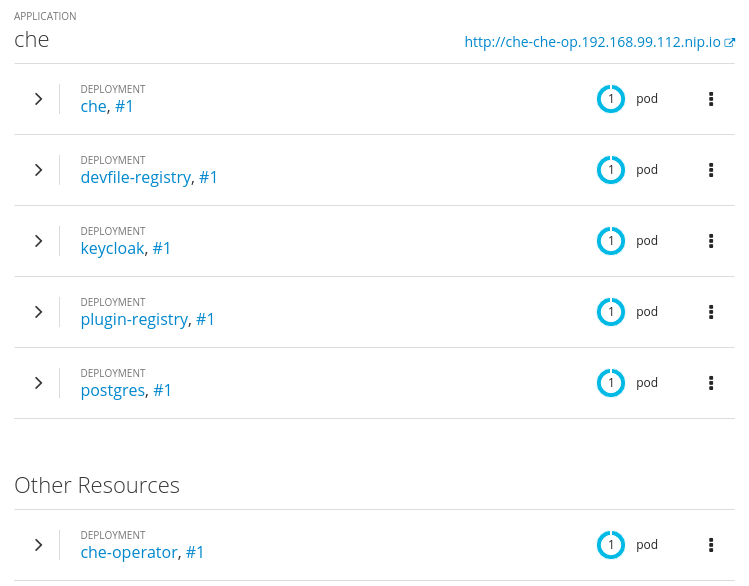
So you want to do Fedora stuff without the hardware headaches and all the vitualization crap?
Well it's finally possible in Windows 10 to run Fedora 31 or even Rawhide (currently 32).
Here's what you need:
1. Update Windows 10 Pro to the latest. Reboot ad nauseum as required.
2. Enable the Windows Subsystem for Linux (WSL) if not already turned on. I used this guide. Reboot again.
3. Open the Microsoft Store and search for Fedora Remix for WSL. It was $5 when I bought it today - figured that was a small price to pay to avoid Alpine, Ubuntu and Debian WSL variants. Shoutout to Whitewater Foundry for the sale price.
4. Launch the new app from Start > Apps > Fedora Remix for WSL
5. This is where things got a bit ... unexpectedly annoying, but I did finally resolve my issue.
6. At the command prompt, run these commands:
sudo suThen I tried to install more stuff...
dnf update -y
dnf install -y buildah podman... but that's when things went sideways:
RPM: error: db5 error(-30969) from dbenv->open: BDB0091 DB_VERSION_MISMATCH: Database environment version mismatch7. After much googling, experimenting with db cache recovery, and learning way more low level rpm db commands than I ever wanted, I found a simple solution:
rm -f /var/lib/.rpm.lock
But somewhere along the way I had tried switching to Rawhide (didn't help!), so to go back to Fedora 31, I did this:9. Back in business, can now install without dnf errors from fc31 packages.
# see current release version at 32 cat /etc/*release # enable/disable repos by hand - no rawhide, only fedora. cd /etc/yum.repos.d/; vim *.repo # out with the new, in with the old yum remove generic-release # re-enable any .repo files that were disabled by the uninstall of Fedora 32 for d in fedora*.rpmsave; do mv $d ${d/.rpmsave}; done # reinstall removed packages dnf history info $(dnf history | grep generic-release | grep Removed | \ sed -e "s#[ ]*\([0-9]\+\) | remove.\+#\1#") # determine which packages were removed dnf history info $(dnf history | grep generic-release | grep Removed | \ sed -e "s#[ ]*\([0-9]\+\) | remove.\+#\1#") | grep Removed | \ grep @@System | sed -e "s#[ ]*Removed \(.\+\).\(noarch\|fc.\+\).*#\1#" # reinstall them yum install --releasever=31 audit fedora-gpg-keys fedora-repos fedora-repos-rawhide \ generic-release generic-release-common initscripts setup shadow-utils # verify back to 31 cat /etc/*release
dnf -y install buildah podman10. Aside: to get a list of all the things you've installed in your Fedora machine, you can run:
dnf -y install hub
dnf -y install python jq pip
...
for i in $(dnf history | grep -v "Altered" | grep install | \
sed -e "s#[\t ]\+\([0-9]\+\)[\t ]\+|.\+#\1#" | tac); do
dnf history info $i | grep Command | \
sed -e "s#.\+ : #dnf -y #";
done
Next up... experimenting with an X server to do Fedora GUI apps inside Windows (without the need for VirtualBox 6.1, which seems to be much tetchier than 6.0 for multi-monitor support).